Understanding Kendall's Tau
My notes from a deep dive into Kendall's Tau coefficient

In my spare time I’ve been helping out my colleague Ed Evans with performance improvements to his Rust-based image processing library imgal. A few weeks ago I discovered a bug in its implementation of Kendall’s Tau coefficient. Having little statistical background, I found the source material on Kendall’s Tau, and all of its variants, rather obtuse for my brain. What I really wanted was intuition - not just the formulas that are readily available, but a clear understanding of how a coefficient is derived from the data. If such intuition exists on the internet, I couldn’t find it.
My goal with this blog post is to encapsulate the knowledge and intuition I gained about Kendall’s Tau and its variants - as such, there are sections describing the actual equations, as well as examples I crafted about my cats to build my own intuition. At the end, I also wrote a bit about how imgal actually uses Kendall’s Tau, and why the variants are necessary over its basic form. Hopefully, this saves others the investment I made into learning these algorithms.
Kendall’s Tau
Suppose you have two cats, Lucy and Penny, who each rank their four toys by preference:
| Toy | Lucy | Penny |
|---|---|---|
| String | 1 | 2 |
| Ball | 2 | 1 |
| Laser | 3 | 3 |
| Mouse | 4 | 4 |
Do they have similar preferences overall? As a cat owner, if they agree, you can focus on buying the types they both enjoy. If they disagree, you’ll need more variety. Measuring this kind of agreement between rankings is called rank correlation, and Kendall’s Tau coefficient is one way to quantify it.
The Formula
Kendall’s algorithm [1] compares pairs of toys. For each pair , it asks: “if Lucy ranked toy better than toy , did Penny also rank toy better?” If so, that pair is concording; if not, it is discording. Kendall’s Tau is:
This same formula appears in formal notation on Wikipedia:
Note the three distinct parts of this formula:
- determines if pair is concording (+1) or discording (-1)
- sums over all unique pairs
- The denominator is the binomial coefficient - the total number of pairs
Note that these two formulas are really just describing the same thing. You find all unique pairs, find the difference between the number of concording and discording pairs, and divide by the total.
Example
Let’s compute Kendall’s Tau for the cats’ toy preferences. For each pair, we can determine concordance by comparing the rankings against the original table:
Pair (i, j) | Did Lucy like i better? | Did Penny like i better? | Concording? |
|---|---|---|---|
| (String, Ball) | Yes | No | No |
| (String, Laser) | Yes | Yes | Yes |
| (String, Mouse) | Yes | Yes | Yes |
| (Ball, Laser) | Yes | Yes | Yes |
| (Ball, Mouse) | Yes | Yes | Yes |
| (Laser, Mouse) | Yes | Yes | Yes |
We have 5 concording pairs, and 1 discording pair, yielding
Now that we have a value, all that is left is to map it to meaning!
Intuition
To build intuition for what different tau values mean, let’s consider three extreme scenarios.
Perfect agreement: If Lucy and Penny had identical rankings (), then for every pair where Lucy preferred , Penny would too. All pairs concord:
Perfect disagreement: If Lucy ranked the toys and Penny ranked them in reverse order (), every pair would discord:
Independence: What if Penny ranked the toys randomly, with no relation to Lucy’s preferences? On average, she’d agree with Lucy on half the pairs and disagree on the other half, giving:
From these edge cases, we can see:
- (tau is always bounded)
- Tau values close to indicate positive correlation (similar preferences)
- Tau values close to indicate negative correlation (opposite preferences)
- Tau values close to indicate no correlation (unrelated rankings)
Hopefully, with some basic intuition about Kendall’s Tau, we can now understand some important variants!
Kendall’s Tau B
There are many situations where rankings have ties. Consider the case where Lucy cannot decide whether she likes the String or the Ball better. In fact, they’re tied for her new favorite toy:
| Toy | Lucy | Penny |
|---|---|---|
| String | 1 | 2 |
| Ball | 1 | 1 |
| Laser | 3 | 3 |
| Mouse | 4 | 4 |
Now, if we consider all of those toy pairs, there’s one pair where we cannot answer whether Lucy liked it better. Such tied pairs are neither concording nor discording, and do not fit cleanly into the Kendall’s Tau formula!
Pair (i, j) | Did Lucy like i better? | Did Penny like i better? | Concording? |
|---|---|---|---|
| (String, Ball) | Tied | No | Lucy Tied |
| (String, Laser) | Yes | Yes | Yes |
| (String, Mouse) | Yes | Yes | Yes |
| (Ball, Laser) | Yes | Yes | Yes |
| (Ball, Mouse) | Yes | Yes | Yes |
| (Laser, Mouse) | Yes | Yes | Yes |
Some implementations of Kendall’s Tau use non-deterministic methods to break any ties (using, for example, Fisher-Yates shuffling [2]) but for scientific applications we require a reproducible approach.
The Formula
Fortunately, Kendall later amended his tau coefficient to encapsulate these cases [3] in a deterministic way. Since ties neither concord nor discord, they’re naturally excluded from the numerator. The denominator, however, incorporates new terms ( and ) to account for ties. Today, this version is called (although he originally called it ):
Note the key differences from basic Kendall’s Tau:
- counts pairs that are tied in the first ranking (Lucy’s rankings in our example)
- counts pairs that are tied in the second ranking (Penny’s rankings in our example)
- The denominator normalizes the sum by the geometric mean of non-tied pairs in each ranking
Let’s see how this works with our cat toy example.
Example
For our example where Lucy created a tie, we can compute the :
With , the cats show strong agreement in their toy rankings. Notice this is higher than the original Kendall’s Tau of from our first example: Lucy’s tie on removed an explicit disagreement, bringing the rankings closer to perfect agreement.
Intuition
The denominator’s construction becomes clearer when we examine how it behaves in different scenarios:
-
Penny also liked the Ball and String equally. Imagine Penny came around to Lucy’s point of view about the String and Ball being equally good:
Toy Lucy Penny String 1 1 Ball 1 1 Laser 3 3 Mouse 4 4 Look at how this now affects :
Now that Penny agrees with Lucy on the tie, the correlation has increased! In other words, agreement on ties is still positive correlation.
-
Penny has a tie elsewhere. Maybe Penny decides one day that the Laser is just as good as the String:
Toy Lucy Penny String 1 2 Ball 1 1 Laser 3 2 Mouse 4 4 Now, if we’d write out the pair table, we’d find two pairings that are tied. is tied for Lucy, and is tied for Penny. Look at how this now affects :
Note that the denominator is the same as scenario 1, however because she tied a different pair, the number of concording pairs has decreased, decreasing the overall correlation. It’s clear that doesn’t just care about how many ties there are, but how many different pairs are affected!
-
Lucy liked everything the same. One day Lucy decides every toy is wonderful and they should all be played with equally:
Toy Lucy Penny String 1 2 Ball 1 1 Laser 1 3 Mouse 1 4 Now, if we’d write out the pair table, we’d find all pairings are tied for Lucy. To compute correlation you need a ranking, and one of our cats has declined to do so. As such, correlation is not possible, and of course will explode:
This is different from , which we saw earlier indicates independent rankings. Here, is undefined because one cat hasn’t actually ranked anything - you can’t measure correlation without a ranking. The fact that is undefined in this case is actually a feature of the metric, because it differentiates between “no correlation” and “no ranking.”
-
Almost fully tied. Note how there is a little correlation to be found if there were one different value in the ranking:
Toy Lucy Penny String 1 2 Ball 1 1 Laser 1 3 Mouse 4 4 Now, if we’d write out the pair table, we’d find only three pairs are tied for Lucy. The other three pairs, , , and , are concording - both cats like the former better, and we have
Intuitively, they’re more positively correlated than anything else, because they agree on the worst toy. Great!
From these scenarios, we see that the denominator elegantly handles rankings with ties: agreement on ties is rewarded (scenario 1) but disagreement is penalized (scenario 2). It provides an intuitive outcome for all-tied rankings (scenario 3), and mostly-tied rankings (scenario 4). Let’s look at another variant!

Weighted Kendall’s Tau
It’s common in statistics to put more emphasis on particular indices within the rankings. For example, I might want to weight my cats’ toy rankings by how long they’ve played with each toy. A cat who’s spent months with a toy knows it brand new and after heavy use—their ranking is more reliable than for a toy they got yesterday.
The Formula
Kendall himself didn’t address weighting, but Grace Shieh did years later [4]. Using notation akin to the unweighted Kendall’s Tau:
The formula is similar to unweighted , but each pair gets multiplied by its pair weight . Shieh’s original formulation uses a general weight function that can depend on both indices, which is useful for more complex weighting schemes [5], but many implementations only support index weights as shown above.
Example
Let’s go back to our example with Lucy and Penny. Suppose they’ve spent 10 hours with the String, 8 hours with the Ball, 2 hours with the Laser, and just 1 hour with the Mouse. I could use these as weights to refine their rank correlation:
| Toy | Lucy | Penny | Weight |
|---|---|---|---|
| String | 1 | 2 | 10 |
| Ball | 2 | 1 | 8 |
| Laser | 3 | 3 | 2 |
| Mouse | 4 | 4 | 1 |
We now can multiply the weights to get a weight value for each pair:
Pair (i, j) | Did Lucy like i better? | Did Penny like i better? | Concording? | Pair Weight = |
|---|---|---|---|---|
| (String, Ball) | Yes | No | No | 80 |
| (String, Laser) | Yes | Yes | Yes | 20 |
| (String, Mouse) | Yes | Yes | Yes | 10 |
| (Ball, Laser) | Yes | Yes | Yes | 16 |
| (Ball, Mouse) | Yes | Yes | Yes | 8 |
| (Laser, Mouse) | Yes | Yes | Yes | 2 |
The weighted Kendall’s Tau would add the weights of all of the concording pairs, subtract the weights of all of the discording pairs, and then divide by the sum of all of the weights:
Intuition
The weighted version mirrors the unweighted version with two key changes:
- Numerator: Each pair gets multiplied by its pair weight instead of counting as 1.
- Denominator: We sum all pair weights () instead of counting pairs.
The dramatic flip from to shows the power of weighting. String vs Ball was the only discording pair, but it had the highest pair weight (80) because both toys were played with extensively. That single heavily-weighted disagreement outweighed all five concording pairs combined (sum of 56). When toys are weighted by play time, Lucy and Penny’s disagreement on their two favorite toys dominates the correlation.
What about ties?
Weighted Kendall’s Tau B
Weighted Kendall’s Tau B combines both extensions: handling ties and using weights. The key intuitions remains the same—instead of summing over pairs, we sum over pair weights, and we alter the denominator to account for ties.
The Formula
Consider the unweighted Kendall’s Tau B:
To write a weighted version , all we need to do is replace pairs with pair weights. Let’s use subscripts to distinguish from the unweighted version:
Example
One final example. Lucy again decides she likes the Ball and the String equally, after 10 hours of play with the String, 8 hours of play with the Ball, 2 hours of play with the Laser, and an hour of play with the Mouse:
| Toy | Lucy | Penny | Weight |
|---|---|---|---|
| String | 1 | 2 | 10 |
| Ball | 1 | 1 | 8 |
| Laser | 3 | 3 | 2 |
| Mouse | 4 | 4 | 1 |
Recall that unweighted was higher than unweighted because Lucy’s tie removed the explicit disagreement, bringing the rankings closer to total agreement.
We’d expect the same pattern here: weighted should be higher than weighted because we’re removing that heavily-weighted String vs Ball disagreement. Let’s compute the pair weights:
Pair (i, j) | Did Lucy like i better? | Did Penny like i better? | Concording? | Pair Weight = |
|---|---|---|---|---|
| (String, Ball) | Tied | No | Lucy Tied | 80 |
| (String, Laser) | Yes | Yes | Yes | 20 |
| (String, Mouse) | Yes | Yes | Yes | 10 |
| (Ball, Laser) | Yes | Yes | Yes | 16 |
| (Ball, Mouse) | Yes | Yes | Yes | 8 |
| (Laser, Mouse) | Yes | Yes | Yes | 2 |
Using this table, we can compute the weighted Kendall’s Tau B:
As expected, is much higher than . The tie neutralized the heavily-weighted disagreement that dominated the weighted calculation, revealing the underlying positive correlation in the remaining pairs.
Finale: The Use Case
As I mentioned at the beginning of this post, I’ve been helping my colleague clean up imgal’s implementation of Weighted Kendall’s Tau B. This metric is a key component of Spatially Adaptive Colocalization Analysis (SACA), a colocalization framework developed by Shulei Wang and our former colleague Ellen Arena [6]. Unlike many of its alternatives, it doesn’t require a human (or AI!) to designate a region of interest and accounts for the spatial characterstics of the data. Programmatic SACA implementations aren’t widely available, so providing a fast, well-documented, and open implementation was one of the core motivations for the creation of imgal.
Colocalization metrics like SACA help scientists quantify how different cellular markers (e.g. fluorescent fusion proteins) correlate and/or co-occur spatially within a sample. To do this, biologists capture multi-channel images of a sample, where each channel excites a different fluorescent target. By quantifying whether (and where) those fluorescent targets colocalize, we can better understand the captured markers’ biological relationships—whether proteins interact, whether cellular processes are coordinated, or whether disease markers cluster together.
To compute colocalization strength, SACA derives rankings for each location in the channel images, and then uses Weighted Kendall’s Tau B to compute a colocalization coefficient. These rankings come from the intensities in a circular neighborhood around each location. Candidate pixels farther away from the center of the neighborhood say less about colocalization than closer neighbors, so SACA uses a weighted Kendall’s Tau, with weights decaying towards the edge of the circle.
In addition, SACA requires a tie-handling variant of Kendall’s Tau because microscopy cameras typically produce images of 16-bit unsigned integers. With a 512x512 image, the pigeonhole principle guarantees some pixels in the image have the same intensity, and they could end up being close together.
SACA is iterative, computing Weighted Kendall’s Tau B for every pixel, multiple times until convergence. A 1024x1024 image means over a million correlation calculations per iteration, making it the performance bottleneck of imgal’s implementation.
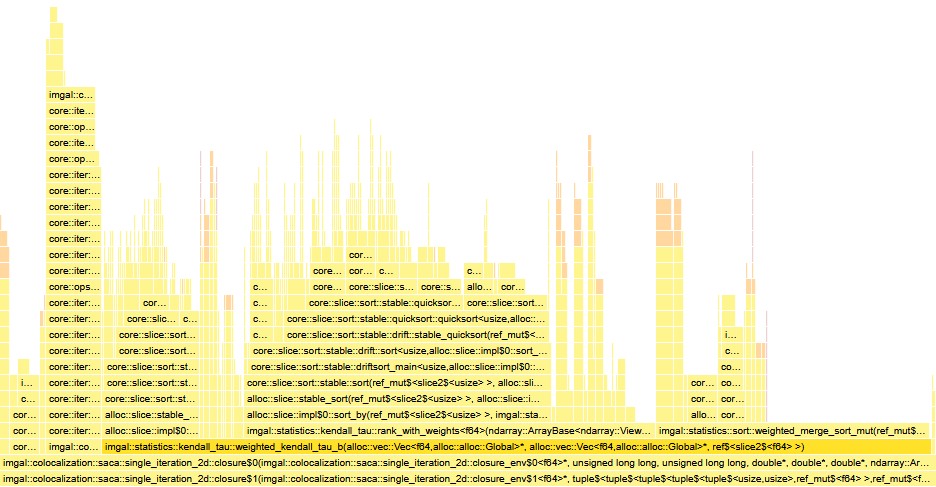
imgal's SACA implementation reveals that Kendall's Tau B (highlighted) accounts for 88% of computation time.To make SACA viable for real biological research, we are motivated to make our Kendall’s Tau implementations fast (and, of course, correct!), and to do that, we must understand all of the algorithm’s variants. As such, I’ve recorded my understanding here—understanding that will hopefully lead to a correct, efficient SACA implementation in imgal.
Acknowledgements
Thanks to my colleague Ed Evans for reviewing this draft and providing valuable technical insights on SACA and colocalization analysis. His feedback greatly improved the accuracy of this post.
References
[1] https://doi.org/10.1093%2Fbiomet%2F30.1-2.81
[3] https://doi.org/10.2307%2F2332303
[4] https://doi.org/10.1016/S0167-7152(98)00006-6
[5] https://doi.org/10.1145/2736277.2741088
[6] https://doi.org/10.1109/tip.2019.2909194